

Databases indices are a concept that are too often overlooked in most courses that talk about backend in general. But they are a very important subject to understand in order to take advantage of the best of your databases, especially in an environment with many queries and a lot of data to search from.
The what and the why of indices#
Database indices are basically an auxiliary data structure which main purpose is to allow for faster search and retrieval of records.
Commonly we perform the indexing of one of the column in the database, the one that has a wide range of unique data, and preferably for which the values are not frequently updated. But the indexing can also be multi-column, for faster retrieval on multiple column queries.
There are many type of data structure that can be applied to index a database column, but the most common one, is a B-tree, a self-balancing tree which makes search, insertion and deletion perform at average and in the worst case scenario in O(log n) time complexity.
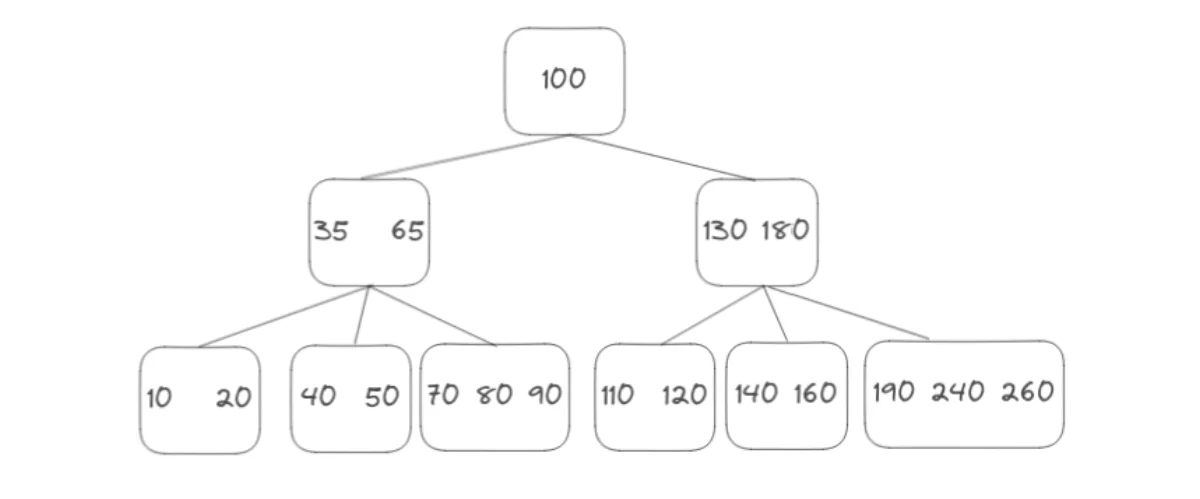
A concrete example#
Let’s try to test this concept in python!
First, let’s create a SQLite database, and in it create a table which simulate a simple e-commerce website. Then insert in it 1M row of random data:
import sqlite3
import time
import random
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()
cursor.execute('''CREATE TABLE orders (
order_id INTEGER PRIMARY KEY,
customer_id INTEGER,
product_id INTEGER,
order_date TEXT,
total_amount REAL);''')
data = [(i, random.randint(1, 10000), random.randint(1, 100), '2023-04-21', random.uniform(1, 1000)) for i in range(1, 1000000)]
cursor.executemany("INSERT INTO orders VALUES (?, ?, ?, ?, ?);", data)
conn.commit()
Now, let’s try a timed query for each record where customer_id is 5000:
start_time = time.time()
cursor.execute("SELECT * FROM orders WHERE customer_id = 5000;")
print(f"Results without index: {len(cursor.fetchall())}")
print(f"Query time without index: {time.time() - start_time:.5f} seconds")
Now, we index the customer_id column, and perform a new query:
cursor.execute("CREATE INDEX idx_customer_id ON orders(customer_id);")
start_time = time.time()
cursor.execute("SELECT * FROM orders WHERE customer_id = 5000;")
print(f"Results with index: {len(cursor.fetchall())}")
print(f"Query time with index: {time.time() - start_time:.5f} seconds")
The whole code together looks like this if you want to test it:
import sqlite3
import time
import random
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()
cursor.execute('''CREATE TABLE orders (
order_id INTEGER PRIMARY KEY,
customer_id INTEGER,
product_id INTEGER,
order_date TEXT,
total_amount REAL);''')
data = [(i, random.randint(1, 10000), random.randint(1, 100), '2023-04-21', random.uniform(1, 1000)) for i in range(1, 1000000)]
cursor.executemany("INSERT INTO orders VALUES (?, ?, ?, ?, ?);", data)
conn.commit()
start_time = time.time()
cursor.execute("SELECT * FROM orders WHERE customer_id = 5000;")
print(f"Results without index: {len(cursor.fetchall())}")
print(f"Query time without index: {time.time() - start_time:.5f} seconds")
cursor.execute("CREATE INDEX idx_customer_id ON orders(customer_id);")
start_time = time.time()
cursor.execute("SELECT * FROM orders WHERE customer_id = 5000;")
print(f"Results with index: {len(cursor.fetchall())}")
print(f"Query time with index: {time.time() - start_time:.5f} seconds")
conn.close()
The results vary according to the performances of the machine, but here are mines:
Results without index: 101
Query time without index: 0.02804 seconds
Results with index: 101
Query time with index: 0.00020 seconds
We can see that with the indices, we get the exact correct results but in less than 1/100th of the time!
The cons of database indices#
If only there were upsides, we would perform indexing on almost every data, at any time. There are unfortunately some downsides that obligates you to evaluate the pros and the cons of indexing in your case, and if it is worth it. Some of the downsides includes:
- Slower writes: Writing to an indexed column can be slower since we cannot just insert in the table, we also need to update the associated index, and sometimes we need to rebalance the tree. If we perform re-indexing operations, it might lock portions of our table, which slows the writings and decrease the concurrency.
- Additional storage necessary: Since the auxiliary data structure needs to be stored in the database, we end up taking more space than without any indices.
- Needed maintenance: To maintain the performances and the relevance of our indices, we need to perform re-indexing of our data regularly, which is an additional process, can takes up some resources and time.