

The big picture of Kafka#
What is Apache Kafka#
In short, Apache Kafka is a distributed publish-subscribe (pub-sub), disk based, messaging system designed for high performance. That means, it can handle high volume, high though put and real time data streams.
When to use Kafka#
Kafka is mainly used to build real-time data pipelines, as a mean to share asynchronously the data or share it with multiple potential consumers. Pretty much whenever we have to handle large amounts of real time data efficiently.
The most common use cases include:
- Real-time data streaming
- Log aggregation
- Monitoring and metrics collection, processing and analyzing
- Commit logging for databases
- Microservices communication
- Event-driven architecture
A zoom on the microservices and the event driven architecture#
Microservices architecture comes with practices that can seems unexpected at first hand. One of them being that choosing asynchronous communication between your microservices is a better choice than going the synchronous way.
By using synchronous communication between your microservices, you are actually slowing down your application, and building what is called, a distributed monolith.
Using asynchronous communication allows your microservices to continue processing new requests without waiting for any response when it sends information. Subscribing multiple services to the same source of information also becomes easier.
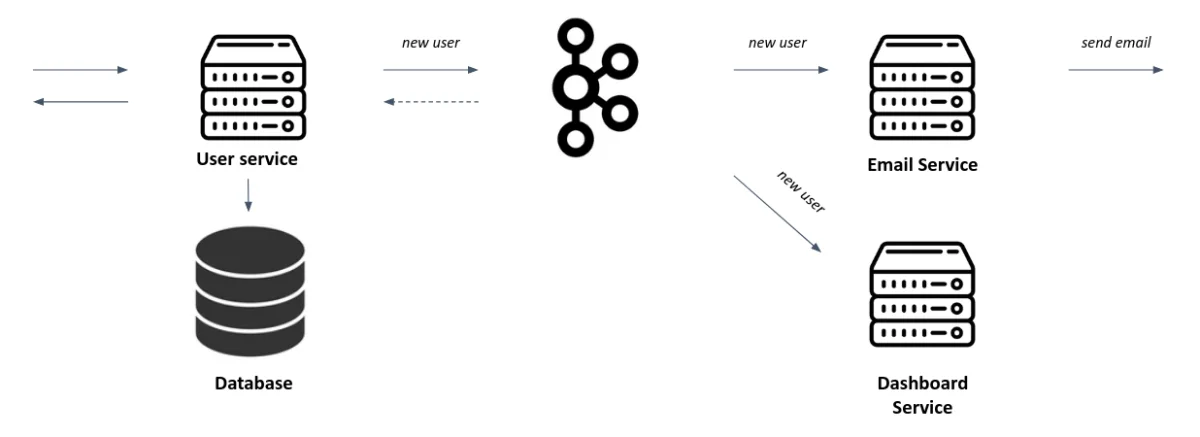
As showed in the above schema, the user service can publish the even new_user which is used by two services, but it doesn’t wait for a response of every service to pursue other processes, it just gets back an acknowledgment from Kafka of the publication of the event.
The user service doesn’t need to know the email service or the dashboard service. We can add as many consumers as we want easily.
Key components of Kafka#
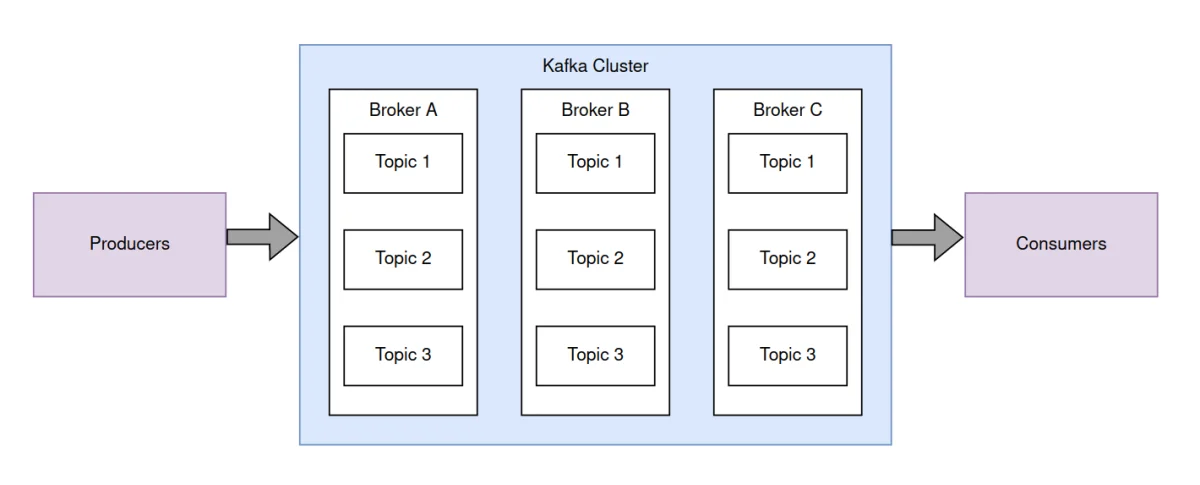
cluster#
A Kafka cluster is the set of machines (brokers) that works together to make the communication system persistent and reliable.
Broker#
A broker is a Kafka server in charge of the topic’s message storage. It handles the incoming and outgoing data streams. Multiple brokers in a distributed architecture are necessary to provide scalability and reliability to the data processing.
Topic#
A topic is a stream of records. Each record in the topic represent a single event or message. You identify a topic by its name, unique in the cluster.
The topics may be partitioned across multiple brokers, in order to provide scalability and allow parallel processing.
They may also be replicated for resilience and a higher availability.
Partition#
The partitions are ordered and immutable sequence of records.
Different partitions of a topic won’t hold the same set of records, but the topic reading order can be respected because in each of the partition, records will be assigned a sequential offset.
Producers#
The producers are the clients that publish records to the topics. Multiple producers can write to a single topic at the same time.
Consumers#
The consumers are the clients that subscribes to one or more topics and receives the messages in real time or by catching up on the previous records.
They are part of a consumer group, which is a set of one or multiple consumers that keep track of the events already read through an offset. This allows consumers to pick up where they left off if a failure were to happen, or assigning a new consumer group to a consumer could allow it to re-consumer the whole topic.
Additional concepts#
- Lag: It is a consumer specific metric, which describe the difference between the latest message in a topic and the latest message consumed