

Leaderless Replication#
All the previously discussed ways of replicating the data were based on the presence of a leader, which would be the node the clients sends data to, and which is then responsible for replicating the data to the other replicas.
Some DB systems take a leaderless approach, where any node can accept writes from clients. It was popular in the early days, and in the most recent years, became fashionably again after being used for Dynamo DB, the Amazon in-house system.
Writing to the database when a node is down#
In a leader-based configuration, when a node ends up offline, we have to perform failover from time to time. That is, designating a new leader to accept writes and get the modifications consumed from. This doesn’t exist in a leader configuration. So, the system will consider a write to be successful, for instance if the majority of the replicas responded ok. On the next read, since the replica that was offline would have a stall (outdated) value, the read is also sent to other nodes, and we check for the most recent value through the version numbers.
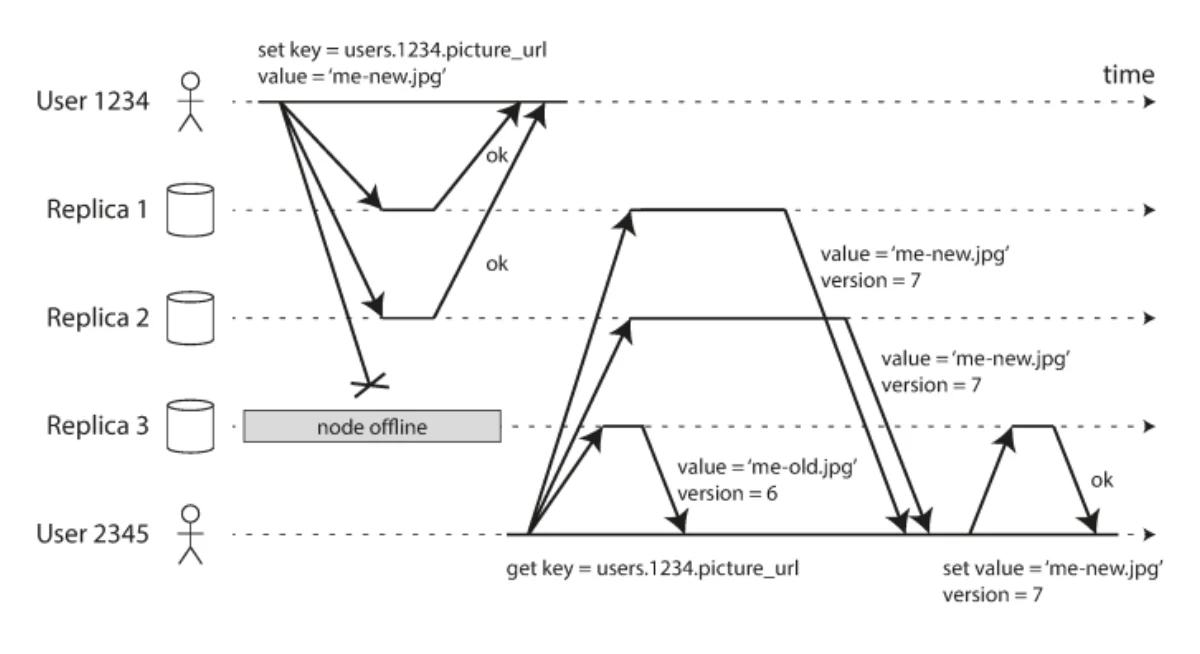
Ensuring data consistency across the cluster#
We should still find ways to ensure that eventually, all the data is copied to every replica. Two common ways of doing so in dynamo-style store, are:
- read repair: When a client reads to several nodes, it will detect the ones with stall data. At read time, we can update the data in the nodes that needs it.
- Anti-entropy process: Background processes constantly looking for difference in the data between different replicas.
Quorum for reading and writing#
The rule directing the validity of write or read operations is called a quorum. It is a minimum number of nodes that must participate in a read (R) or write (W) operation for it to be considered successful.
With N total nodes:
- Write quorum (W): Number of nodes that must acknowledge a write
- Read quorum (R): Number of nodes that must respond to a read
- Key rule: R + W > N ensures consistency by guaranteeing read and write operations overlap on at least one node.
Example with N=5: W=3 (write to 3 nodes) R=3 (read from 3 nodes) 3+3>5, so consistency is maintained, and we can tolerate up to two unavailable nodes.
This helps balance consistency and availability while tolerating node failures.
If fewer than the required W or R nodes are available, write or reads return an error.
Limitations of Quorum Consistency#
We can expect to read most recent values with quorums W + R > N, especially since setting both W & R values to be more than N/2, because the quorum condition is respected, and our system can tolerate up to N/2 nodes failures.
But this comes with latency and lower availability than if we chose lower values for W & R such as W + R <= N (quorum condition not respected). In this case, lower numbers of successful responses are required for the operations to succeed. This is a tradeoff for a higher chance of reading stale values.
With the quorum condition W + R > N, we still have some edge cases that leads to stale values reads, such as when a sloppy quorum is used, two writes happening concurrently, a write happening concurrently to a read, failure from a node carrying a new value.
Sloppy Quorums and Hinted Handoff#
Appropriately configured quorums allows the tolerance to individual node failure without failover, as well as the possible slowness of some node since we can return on W or R responses which are lower than N. These makes databases with leaderless replication appealing for use cases which require high availability and low latency, and which can tolerate occasional stale reads.
Unfortunately, network failures can still happen, making the quorums not as fault-tolerant as they could be. It is possible that a client can only connect to a certain number of nodes that would be insufficient to satisfy a quorum. When this happens, database designers face the following trade-off:
- Return errors to all requests for which we cannot reach a quorum of W or R nodes.
- Accept writes anyway, and write them to some nodes that are reachable, but not among the n nodes.
The latter is known as a sloppy quorum, where writes and reads still require W and R successful responses, but those may include nodes that are not among the designated N “home” nodes for a value. Once the network interruption is fixed, any writes that one node temporarily accepted on the behalf of another node are going to be sent to the appropriate “home” node. This is called _hinted handoff.
A sloppy quorum isn’t a real quorum in the traditional sense, but gives assurance of durability of the cluster. It is very efficient to increase the write availability of a cluster.
Detecting concurrent writes#
Since several clients can write concurrently to the same key, conflicts can happen even with strict quorum. Also, in a dynamo-style database, conflict may happen during read repair, or hinted handoff.
To become eventually consistent, the replicas should converge towards the same value, which they seldomly/incompletely do in the databases implementations.
Note that concurrent operation are operations unaware of each others. It doesn’t mean they occurred “at the exact same time”, as network slowness or interruption could lead to similar confusion as if two operation were perfectly overlapping.
Different approach to go toward eventual consistency with leaderless clusters are:
- Last write wins: A simple but potentially dangerous approach where each replica only stores the most “recent” value, typically using timestamps. While it ensures eventual convergence, it can silently discard writes, even non-concurrent ones. It’s only safely used when keys are written once and treated as immutable, like using UUIDs as keys.
- Happens-before relationship: A method to determine if operations are concurrent based on whether one operation knows about or depends on another. If operation B knows about or builds upon operation A, then A happens-before B. Operations are concurrent if neither happens-before the other.
- Version tracking: Each write gets an incremented version number, and clients must include the version number from their previous read when writing. Servers keep all values with higher version numbers (concurrent writes) while allowing overwrites of lower version numbers. This prevents data loss but requires client-side merging of concurrent values.
- Merging concurrent values: When concurrent writes occur, the system creates “siblings” that must be merged. For example, a shopping cart might merge by taking the union of items, but special handling (tombstones) is needed for deletions. Some systems use CRDTs (Conflict-free Replicated Data Types) to automate this merging.
- Version vectors: An extension of version tracking for multiple replicas, where each replica maintains its own version number and tracks others’ versions. This helps distinguish between overwrites and concurrent writes across replicas, while ensuring safe reads and writes between different replicas.
Wrapping up#
After diving into the 5th chapter of DDIA, the following notions should be understood and well-defined:
Core Benefits of Replication:
- High Availability: System continues running despite machine failures
- Disconnected Operation: Applications work during network interruptions
- Reduced Latency: Data placed closer to users
- Improved Scalability: Handle more reads through replicas
Replication Approaches:
- Single-leader: All writes go to one leader node; followers get updates from leader
- Multi-leader: Multiple nodes accept writes; leaders exchange updates
- Leaderless: Writes and reads go to several nodes in parallel
Key Consistency Concepts:
- Read-after-write: Users always see their own writes
- Monotonic reads: Users don’t see older data after seeing newer data
- Consistent prefix reads: Users see causally related events in correct order
Replication Methods:
- Synchronous: Waits for replica confirmation
- Asynchronous: Continues without waiting, but risks data loss during failures
The chapter emphasized that while replication seems straightforward, it involves complex trade-offs between consistency, availability, and latency, especially when handling network failures and concurrent updates.