

Multi-Leader replication#
Single leader replication present the downside that if we cannot connect to the leader, we cannot write to the database.
Multi-leader replication (also known as master-master or active/active replication) solves this by allowing multiple nodes to accept writes, with each of these master nodes following each others.
Use case for multi-leader replication#
Multi-leader replication rarely makes sense in a single datacenter setup, as it adds a lot of complexity for little benefits.
Multi-datacenter operation#
In a setup with multiple datacenters, we can now have one leader per datacenter instead of the only leader in one of the datacenters. The differences are the followings:
- Performance: Each write has to go over the internet to the DC which has the leader node in a single-leader configuration. In a multi-leader configuration, we avoid that, so the data travel time is reduced aswell as the latency. Also, as the replication to the other datacenters is asynchonous, the network dekay is hidden from the user.
- Tolerance to datacenter outages: In a single-leader config. failover is the way to deal with an outage of the leader node. In a multi-leader config. each datacenter can continue to operate independently, and replication catches up after the recovery.
- Tolerance to network problems: Traffic between datacenters id often made across the internet, which is a less reliable network than a local newtork in a datacenter. As single-leader replication often comes with synchronous writes distribution to the different data centers, this can be less reliable than multi-leader replication for which the replication is made asynchronously.
Multi-leader replication is considered dangerous because of many possible issues, such as write conflicts, problems with auto-incrementing keys, etc… It should be used only when necessary.
Clients with offline operation#
Multi-leader replication is appropriate for applications that need to work offline.
For instance, a calendar app which would allow the user to see and edit/create events (read & write requests), regardless of the network connection. The app would then sync the changes when the network is available.
In this instance, each instance (different apps on different devices) would have a local database, and an asynchronous multi-leader replication would be used to sync the changes between the different instances.
From an architecture point of view, this setup is similar to a multi-leader replication between different datacenters, where each device is a datacenter, and the network between them is extremely unreliable.
Collaborative editing#
Collaborative editing is when multiple users can edit a document at the same time. It has a lot of similarities with the offline operation use case.
When one user edits a document, the changes are instantly applied to their local replica, and asynchronously replicated to the server and to the other users.
One way to deal with conflicts would be to lock the document for a user edits the document. But this would make impossible for multiple users to edit the document at the same time. To make simultaneous collaboration possible, the unit of change can be made smaller, or lock can be avoided altogether. This would imply to resolve conflicts when they happen.
Handling write conflicts#
Write conflicts are the main issue with multi-leader replication. They happen when two nodes accept writes concurrently, and then replicate the writes to the other nodes.
An example of this would be if at the same time, two users edited the title of a document, and then saved their changes. The two changes would then be asynchronously replicated to the other nodes, and this would result in a conflict.
There are different ways to handle write conflicts:
Synchronous versus asynchronous conflict detection: Synchronously detecting conflicts would allow the leader to reject the write if it detects a conflict. But doing so would lose the main benefit of multi-leader replication, which is the ability to accept writes on each leader independently. If we choose to detect conflicts synchronously, we would be better off with a single-leader replication.
Conflict avoidance: One way to avoid conflicts is to simply avoid them: by making sure that all the writes for a certain record are directed to the same leader. This can be done by hashing the record’s ID, or by using a central coordination service to assign a record to a leader. However, in the case where we need to change a designated leader for a record, conflicts avoidance would be impossible.
Converging toward a consistent state: A single leader database, writes are applied in a sequential order, which makes the final state clear. In a multi-leader replication, with asynchronous replication, each replicas cannot apply writes in the order they were received, or it would end up with an inconsistent state. The replicas must resolve the conflicts in a convergent way, which means that they arrive at the same final value after all the changes have been replicated. This can be done in multiple ways:
- Last write wins: The last write to a record is the one that is kept. This is the simplest way to resolve conflicts, but it can lead to data loss. It is possible to apply this “priority” logic to one leader which would have been given a higher id, resulting in a precedence in case of conflict.
- Merge values: The values are merged together. This is more complex, but it can be done in some cases. For instance, if two users edit the same document, the changes can be merged together.
- Custom conflict resolution logic: In some cases, we may need to write custom conflict resolution logic. For instance, if two users edit the same document, we may want to ask the users to resolve the conflict themselves.
Multi-Leader replication topologies#
A replication topology is the way the nodes are connected to each other for replication, that is, the way writes are propagated from one node to another.
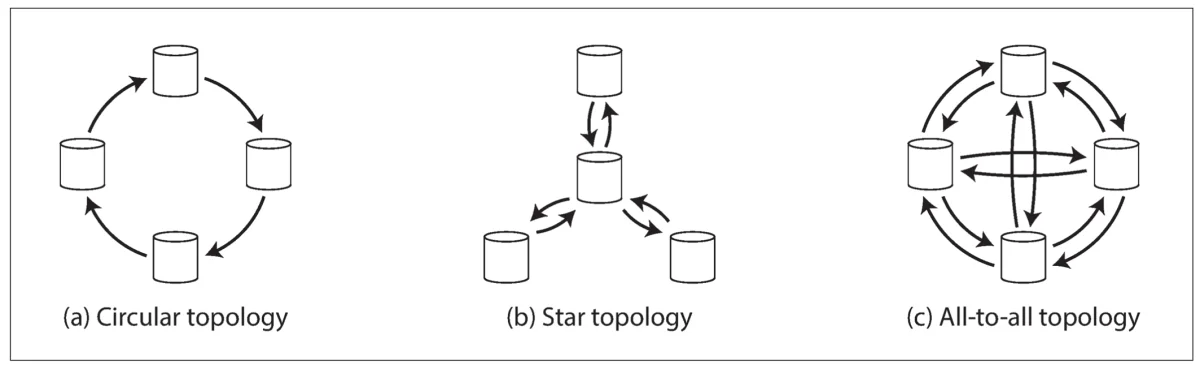
The most common topology is the all-to-all topology, where each node is connected to every other node. Other typologies include the star topology, where each node is connected to a single central node, and the circular topology, where each node is connected to two other nodes.
One of the main risk with topologies like the circular or star ones, which needs a write to go through multiple nodes before being applied, is that if one node is slow or unavailable, the whole system is slowed down or unavailable.