

Chapter 2: Data models and query languages#
Data models have effects on how the software is written, but also on how we think about the problem we are solving.
SQL is maybe the best-known data model today.
NoSQL, which is more recent, aim to solve different problems:
- A need for greater scalability then relational database can easily achieve, including very large datasets, or high write thoughput.
- Specialized query operations that are not well supported by the relational model
- Frustration with the restrictiveness of relational schemas. The desire for a more dynamic and expressive data model.
With a one to many relationship (e.g the résumé of a linkedin user may have multiple experiences) In traditional SQL model, the most normalized representation for a one to many relationship would have been to put the “many” in a separate table, with foreign key reference to the “one” table. Later versions of the SQL standard added support for structured datatypes, and XML or JSON data. Allowing for multi-valued data to be stored in a single row. A third option would have been to encode the “many” informations as a single JSON or XML document, and store it as a text column in the database.
For a data structure like a résume, a self-contained document, a JSON, can be very appropriated. That’s what we would find in NoSQL databases. Some developers think that JSON models reduces the impedence missmatch between the application code and the storage layer (i.e the disconnect betweed the different models).
The JSON representation has a better locality. With the multi-table schema, we either need to perform multiple queries, or a messy multi-way join. With the JSON representation, one query is sufficient.
Many-to-one and many-to-many relationships#
For the region field in our résumé model we would prefer not to give the user a text field to enter the region but the id to link to a standardized row from an existing list of regions. This is more standardized, permits drop-down, autocompletion, avoid spelling errors, avoid embiguity, easier to update, localization support, better search, etc… In many cases, if we can use standardized lists, it might be a good idea. Removing duplication is the key idea behind normalization in databases.
Normalizing our data then requires many-to-one relationships. It is normal in relational db to reference rows from other tables by ID, we can make joins easily.
NoSQL db may be repeating history, in the sense that back in the past, IBM’s IMS had some similarities to how are stored JSON documents. It worked well for one to many relationships but not many to many, and didn’t support joins.
The a relational database, the query optimizer automatically decides which parts of the query to execute in which order, and which indexes to use.
Relational db vs Document db#
There are many aspects to consider when choosing between the relational db vs document db, like the fault-tolerance properties, or handling concurrency.
But on the matter of the difference in data model: Document data model offer schema flexibility, better performances due to locallity, and it might be closer to the data structure of the application. The relational model offers better support for joins, many-to-one and many-to-many relationships.
To choose which type of db would lead to the simplest application code, the main argument willbe the kind of relationships the exist between the data items (e.g, almost no relationships: go with document database)
In document db, no schema is enforced in the database. It is often an implicit schema, that is assumed by the code. We can talk about schema-on-read for document db (schema is only assumed on read), and schema-on-write for relational db. It can be seen as similar to dynamic (runtime) time checking in programming languages, which would be schema-on-read, vs static type checking (complile-time) which would be the schema-on-write.
You are way less flexible in your schema with relational db, but you can still ALTER TABLE and UPDATE it. If the data is heterogeneous, the schema-on-read aproach is still advantageous (if the items in the collection don’t all have the same structure)
Document db stores has a performance advantage du to storage locality. The data is not split across tables, so we need to lookup only one index. The locallity advantage applies if we need need a large part of the document, because for reads or write, the whole document will be loaded.
Relational and document db are converging over time, with relational databases being able to support documents, index and query inside those documents, and documents db developing to offer joins in query language.
Query languages for data#
In a declaratice query language like SQL, we only specify the pattern of the data we want (what condition the result must meet, and how the data must be transformed), not how it must achieve it. As opposed to what would be an imperative query language, which would imply to write down every step to follow (like programming languages). It is up to the db system’s query optimizer or decide which index and which joins methods to use.
Declarative query languages also lend themselves to parallel execution, which is great with todays multiple core CPUs. It is way harder to parallelize imperative code across multiple cores and multiple machines, since the instructions specified must be performed in a particular order.
On another note, CSS is another example of the advantage of declaratice over imperative.
MapReduce is a programming model for processing large amounts of data in bulk across many machines, popularized by Google. It is somewhere in between declarative languages and imperative query APIs: the logic of the query is expressed with snipped of code, which are called repeatedly by the processing framework. It is supported in a limited form by some NoSQL datastrore, including MongoDb, in which, its application is pretty straightforward: we declare a map function that will be ran on every document we are seeing, which will returns a key, value pair of our choice. And then we declare a reduce function that will perform a folding operation on all the returns of the map function with the same key value.
db.observations.mapReduce(
function map() {
var year = this.observationTimestamp.getFullYear();
var month = this.observationTimestamp.getMonth() + 1;
emit(year + "-" + month, this.numAnimals);
},
function reduce(key, values) {
return Array.sum(values);
},
{
query: { family: "Sharks" },
out: "monthlySharkReport"
}
);
map and reduce must be pure functions (no side effect && always the same output for the same input). This allows for the efficient distribution of the processing of the query.
Graph like data models#
A graph is composed of:
- nodes (or vertices, entities)
- edges (or relationships or arcs)
A graph model is the most appropriated when many-to-many relationships are very common in our data. They provide the advantages of using well known optimal algorithms to operate on the graphs. For instance shortest path algorithms on a road network, or the page rank algorithm on web pages.
We know graphs where the nodes are the same kind of thing (people, locations, web page, etc…), but some graphs represent completely different types of objects in a single data store. For instance, facebook has a single graph with many different types of nodes, representing people, locations, events, checkins, comments, etc… The edges represents different relations like which person is friend which who, what event happened in which location, etc…
Property graphs:
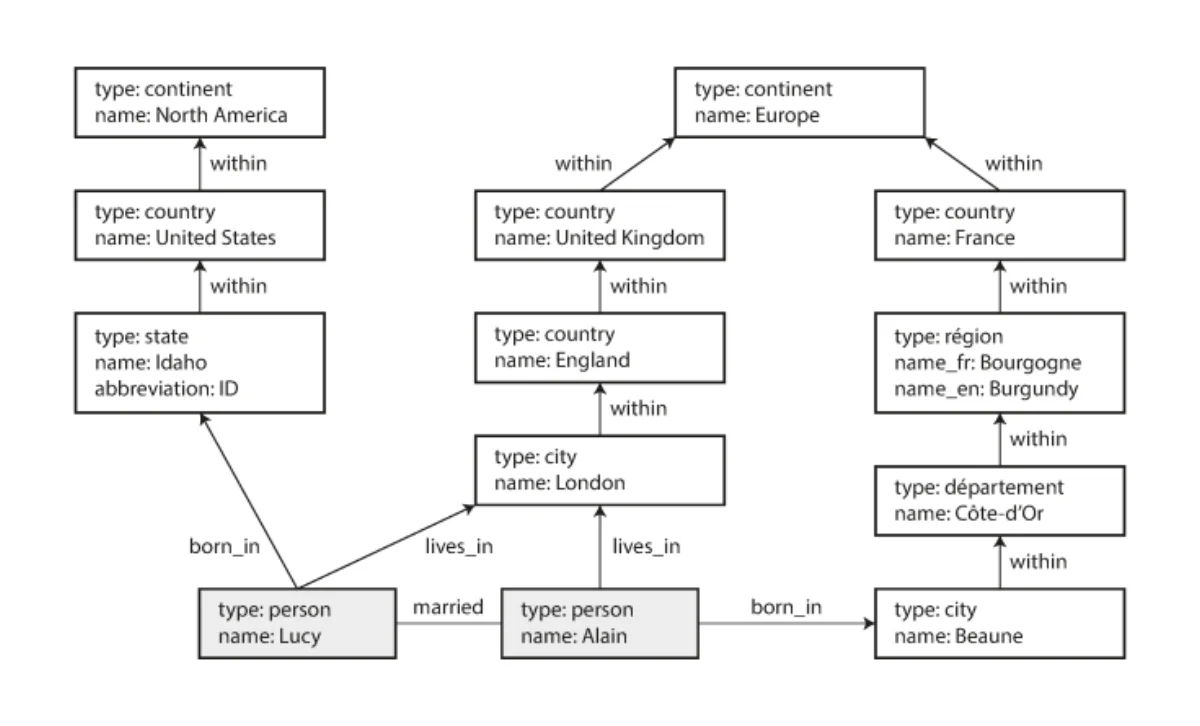
In the property graph, each node consist of:
- a unique id
- a set of outgoing edges
- a set of incoming edges
- a collection of properties (key-value pairs) Each edge consist of:
- a unique id
- the node at which the edge starts (tail)
- the node at which the edge ends (head)
- a label to describe the kind of relationship between the two nodes
- a collection of properties (key-value pairs)
Storing our graph would be like having two tables, one for edges and one for nodes.
Graphs are great for evololvability, we can add new type of nodes and edges on the go. We just have to adapt the application code.
There exists graph database management systems like neo4j, that are made to store and process these kind of data structure efficiently, and the can come with a query language designed for these exact usecases (e.g Cypher, a declarative query language for Neo4j)
The issue with doing graph queries using SQL, is that, in relational databases, we do need to know in advance which joins we need. When in a graph query we may need to traverse a variable number of edges before finding the node we are looking for.
The same query will be way longer and way more complex in SQL than in Cypher.
Triple stores and SPARQL#
The triple-store model is mostly equivalent to the property graph model, using different words to describe the same ideas.
In a triple-store, all information is stored in the form of very simple three-part statements: (subject, predicate, object). For example, in the triple (Jim, likes, bananas), Jim is the subject, likes is the predicate (verb), and bananas is the object.
The subject would be the equivalent of a node. The object could be either:
- A value in a primitive datatype. e.g: (lucy, age, 33) would be a node lucy with the property {“age”: 33}
- Another node in the graph. In which case, the predicate is an edge in the graph. e.g (lucy, marriedTo, alain)
The fondation: Datalog#
Datalog is a much older language than SPARQL or Cypher.
It is pretty similar to the triple-store model. Instead of writing triples as (subject, predicate, object), we write it as predicate(subject, object).
Summary#
We saw that historically, data started out being represented as one bug tree (the hierarchical model).
But as it was not efficient to represent many-to-many relationships, the relational model was invented.
Nowadays, as the relational model is not the perfect fit for all applications, new NoSQL datastores have emerged:
- Document databases, which target use cases where data can be self-contained in document for which the relationships are rare.
- Graph databases, in which, on the contrary, anything can be ralated to everything.
In both Document and Graph db, you usually don’t enforce a schema on the data they store, in opposition to the relational db. But the application code still need to make assumtions that the data has a certain structure.